library(xplainfi)
library(mlr3learners)
#> Loading required package: mlr3
library(data.table)
#>
#> Attaching package: 'data.table'
#> The following object is masked from 'package:base':
#>
#> %notin%
library(ggplot2)There are multiple inference methods available for different importance methods and estimation targets. The approaches fall into two broad categories:
Resampling-based variability: When importance is estimated via resampling (e.g., subsampling), we obtain multiple importance estimates across iterations. We can summarize this variability descriptively (empirical quantiles), or use parametric methods, either naive (raw CIs) or corrected for the dependence structure of resampling (Nadeau & Bengio).
Observation-wise inference on test data: When a dedicated test set with i.i.d. observations is available (e.g., holdout), we can use observation-wise loss differences for formal statistical inference. This is the basis for CPI/cARFi (conditional importance) and the Lei et al. method (LOCO inference).
Setup
We use a simple linear DGP for demonstration purposes where
- \(X_1\) and \(X_2\) are strongly correlated (r = 0.7)
- \(X_1\) and \(X_3\) have an effect on Y
- \(X_2\) and \(X_4\) don’t have an effect
task = sim_dgp_correlated(n = 2000, r = 0.7)
learner = lrn("regr.ranger", num.trees = 500)
measure = msr("regr.mse")DAG for correlated features DGP
Resampling-based variability
When we compute feature importance with resampling — for example,
subsampling with multiple repeats — each resampling iteration yields a
separate importance estimate. By default, $importance()
simply averages these estimates without reporting any measure of
variability:
pfi = PFI$new(
task = task,
learner = learner,
resampling = rsmp("subsampling", repeats = 15),
measure = measure,
n_repeats = 20 # for stability within resampling iters
)
pfi$compute()
pfi$importance()
#> Key: <feature>
#> feature importance
#> <char> <num>
#> 1: x1 6.438492669
#> 2: x2 0.096075680
#> 3: x3 1.794307978
#> 4: x4 -0.001031032There are several ways to quantify the variability of these estimates, ranging from purely descriptive to parametric inference.
Empirical quantiles
The simplest approach is to look at the empirical distribution of importance scores across resampling iterations. This is not a formal inference method — it merely describes the observed variability without any distributional assumptions.
The "quantile" method returns only confidence bounds
(conf_lower, conf_upper) without
se, statistic, or p.value, since
empirical quantiles are not a statistical test. The conf_*
naming is kept for consistency with other methods to ease
visualization.
pfi_ci_quantile = pfi$importance(ci_method = "quantile", alternative = "two.sided")
pfi_ci_quantile
#> Key: <feature>
#> feature importance conf_lower conf_upper
#> <char> <num> <num> <num>
#> 1: x1 6.438492669 6.069884413 6.941655631
#> 2: x2 0.096075680 0.074212298 0.119418944
#> 3: x3 1.794307978 1.712816839 1.882614290
#> 4: x4 -0.001031032 -0.003989459 0.000776648Raw confidence intervals
A natural next step is to assume the importance scores are approximately normally distributed across resampling iterations and compute t-based confidence intervals. However, these unadjusted confidence intervals are too narrow and hence invalid for inference: the resampling iterations share overlapping training sets, violating the independence assumption underlying the t-distribution.
pfi_ci_raw = pfi$importance(ci_method = "raw", alternative = "two.sided")
pfi_ci_raw
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 6.438492669 0.076085973 84.621283 2.258096e-20 6.275304487
#> 2: x2 0.096075680 0.003812197 25.202183 4.589294e-13 0.087899331
#> 3: x3 1.794307978 0.013566832 132.256961 4.384134e-23 1.765210018
#> 4: x4 -0.001031032 0.000347573 -2.966375 1.020949e-02 -0.001776502
#> conf_upper
#> <num>
#> 1: 6.6016808513
#> 2: 0.1042520290
#> 3: 1.8234059392
#> 4: -0.0002855619The parametric CI methods ("raw" and
"nadeau_bengio") return se,
statistic, p.value, conf_lower,
and conf_upper. The alternative parameter
controls whether a one-sided test ("greater", the default,
testing H0: importance <= 0) or two-sided test
("two.sided") is performed. Here we use
alternative = "two.sided" for visualization purposes so
that conf_upper is finite.
Corrected t-test (Nadeau & Bengio)
To account for the dependence between resampling iterations, we can use the correction proposed by Nadeau & Bengio (2003) and recommended by Molnar et al. (2023). This inflates the variance estimate to account for the overlap between training sets, yielding wider (and more honest) confidence intervals:
pfi_ci_corrected = pfi$importance(ci_method = "nadeau_bengio", alternative = "two.sided")
pfi_ci_corrected
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 6.438492669 0.221900229 29.015259 6.610673e-14 5.962564012
#> 2: x2 0.096075680 0.011118046 8.641418 5.518158e-07 0.072229844
#> 3: x3 1.794307978 0.039566861 45.348757 1.357598e-16 1.709445501
#> 4: x4 -0.001031032 0.001013676 -1.017122 3.263518e-01 -0.003205151
#> conf_upper
#> <num>
#> 1: 6.914421327
#> 2: 0.119921517
#> 3: 1.879170456
#> 4: 0.001143087The Nadeau-Bengio correction provides better (but still imperfect) coverage compared to the raw approach.
Comparison
To highlight the differences between all three approaches, we visualize them side by side:
pfi_cis = rbindlist(
list(
pfi_ci_raw[, type := "raw"],
pfi_ci_corrected[, type := "nadeau_bengio"],
pfi_ci_quantile[, type := "quantile"]
),
fill = TRUE
)
ggplot(pfi_cis, aes(y = feature, color = type)) +
geom_errorbar(
aes(xmin = conf_lower, xmax = conf_upper),
position = position_dodge(width = 0.6),
width = .5
) +
geom_point(aes(x = importance), position = position_dodge(width = 0.6)) +
scale_color_brewer(palette = "Set2") +
labs(
title = "Parametric & non-parametric CI methods",
subtitle = "RF with 15 subsampling iterations",
color = NULL
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")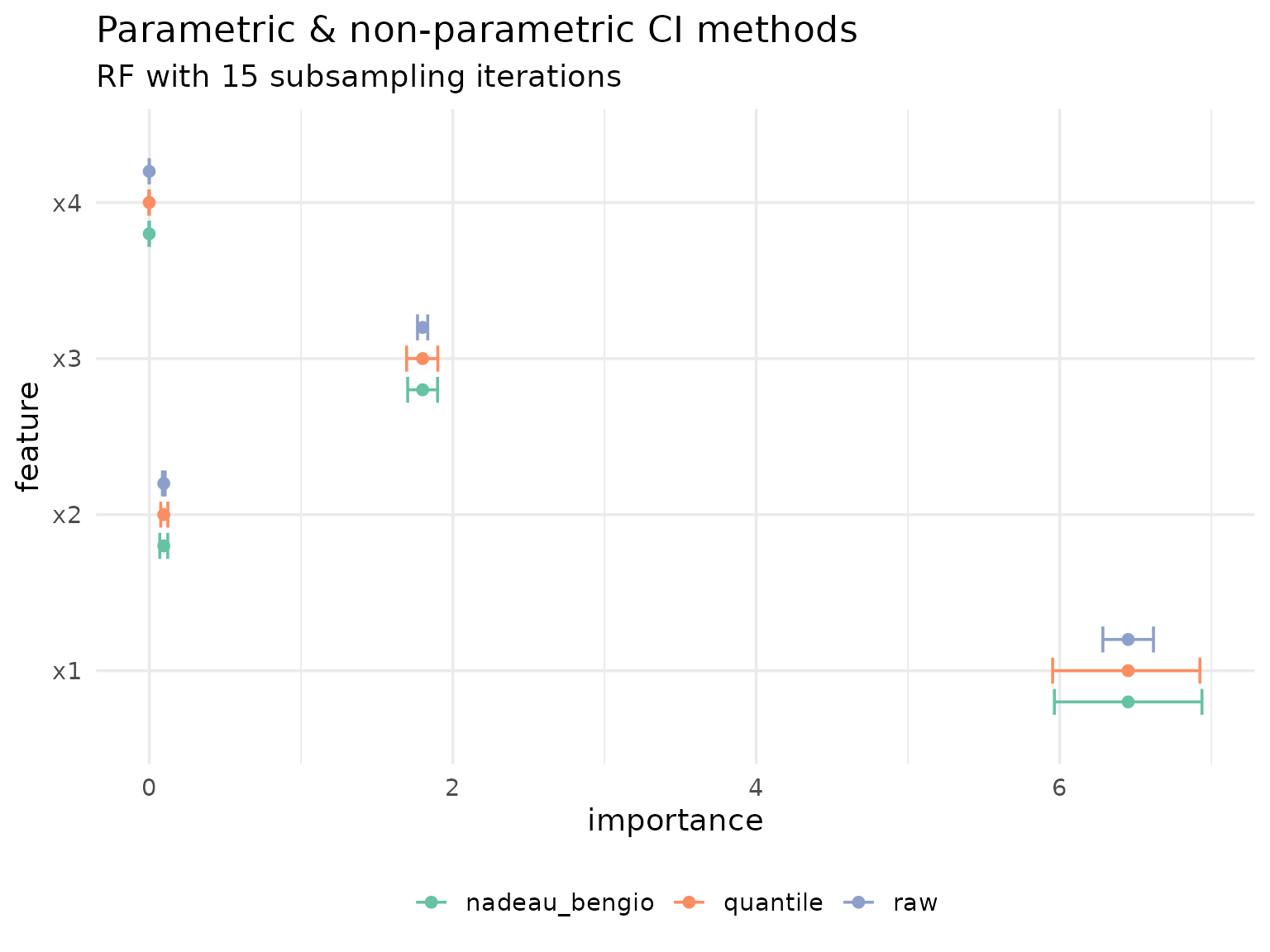
The results highlight just how optimistic the unadjusted, raw confidence intervals are.
Multiplicity correction
When testing many features simultaneously, p-values should be adjusted to control the overall error rate. There are two main frameworks for multiplicity correction:
Family-wise error rate (FWER): The probability of making at least one false rejection among all tests. FWER control is the more conservative approach and is appropriate when any single false positive would be costly. Methods include Bonferroni (\(\alpha / k\)) and Holm (a step-down variant that is uniformly more powerful than Bonferroni while still controlling FWER).
False discovery rate (FDR): The expected proportion of false rejections among all rejected hypotheses. FDR control is less conservative and better suited for exploratory analyses where some false positives are tolerable. The most common method is Benjamini-Hochberg (BH).
The p_adjust parameter accepts any method from
stats::p.adjust.methods and defaults to "none"
(no adjustment).
pfi$importance(ci_method = "nadeau_bengio", alternative = "two.sided", p_adjust = "none")
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 6.438492669 0.221900229 29.015259 6.610673e-14 5.962564012
#> 2: x2 0.096075680 0.011118046 8.641418 5.518158e-07 0.072229844
#> 3: x3 1.794307978 0.039566861 45.348757 1.357598e-16 1.709445501
#> 4: x4 -0.001031032 0.001013676 -1.017122 3.263518e-01 -0.003205151
#> conf_upper
#> <num>
#> 1: 6.914421327
#> 2: 0.119921517
#> 3: 1.879170456
#> 4: 0.001143087With Bonferroni correction (FWER control), both p-values and confidence intervals are adjusted. The confidence intervals use an adjusted significance level of \(\alpha / k\) where \(k\) is the number of features:
pfi$importance(ci_method = "nadeau_bengio", alternative = "two.sided", p_adjust = "bonferroni")
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 6.438492669 0.221900229 29.015259 2.644269e-13 5.655275139
#> 2: x2 0.096075680 0.011118046 8.641418 2.207263e-06 0.056833502
#> 3: x3 1.794307978 0.039566861 45.348757 5.430393e-16 1.654653056
#> 4: x4 -0.001031032 0.001013676 -1.017122 1.000000e+00 -0.004608896
#> conf_upper
#> <num>
#> 1: 7.221710199
#> 2: 0.135317858
#> 3: 1.933962901
#> 4: 0.002546832For sequential or adaptive procedures such as Holm (FWER) or Benjamini-Hochberg (FDR), only p-values are adjusted. These methods do not yield a clean per-comparison \(\alpha\) that could be used for CI construction, so confidence intervals remain at the nominal level:
pfi$importance(ci_method = "nadeau_bengio", alternative = "two.sided", p_adjust = "BH")
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 6.438492669 0.221900229 29.015259 1.322135e-13 5.962564012
#> 2: x2 0.096075680 0.011118046 8.641418 7.357544e-07 0.072229844
#> 3: x3 1.794307978 0.039566861 45.348757 5.430393e-16 1.709445501
#> 4: x4 -0.001031032 0.001013676 -1.017122 3.263518e-01 -0.003205151
#> conf_upper
#> <num>
#> 1: 6.914421327
#> 2: 0.119921517
#> 3: 1.879170456
#> 4: 0.001143087This applies to all ci_methods that produce p-values
("raw", "nadeau_bengio", "cpi",
"lei").
Observation-wise inference on test data
The resampling-based approaches above quantify variability due to the choice of train/test split. A different approach uses observation-wise loss differences on a test set for formal statistical inference.
The idea is straightforward: for each test observation, we compare the loss with and without a feature (either by perturbing the feature or by retraining the model without it). The resulting per-observation importance scores are i.i.d. under appropriate conditions, enabling standard statistical tests.
Inference is guaranteed to be valid with a single train/test split (holdout), where test observations are truly i.i.d. and the model is fixed. Other resampling strategies may be used but come with caveats (see below).
- CPI / cARFi for conditional feature importance (perturbation-based, model is fixed per resampling iteration)
- Lei et al. for LOCO importance (retraining-based, model is refitted without each feature)
Conditional predictive impact (CPI)
CPI (Conditional Predictive Impact) was introduced by Watson & Wright (2021) for statistical inference with conditional feature importance using knockoffs. Two main approaches are supported:
- CPI with knockoffs: The original method using model-X knockoffs for conditional sampling.
-
cARFi (Blesch et al., 2025): Uses Adversarial
Random Forests for conditional sampling, which works without Gaussian
assumptions and supports mixed data. CPI is originally implemented by the cpi
package. It works with
mlr3and its output on our data looks like this:
cpi_res = cpi(
task = task,
learner = learner,
resampling = resampling,
measure = measure,
test = "t"
)
setDT(cpi_res)
setnames(cpi_res, "Variable", "feature")
cpi_res[, method := "CPI"]
cpi_res
#> feature CPI SE test statistic estimate
#> <char> <num> <num> <char> <num> <num>
#> 1: x1 4.5869424151 0.1431664627 t 32.0392243 4.5869424151
#> 2: x2 0.0059452604 0.0031447720 t 1.8905219 0.0059452604
#> 3: x3 1.7932108925 0.0568503126 t 31.5426743 1.7932108925
#> 4: x4 -0.0001760563 0.0006907253 t -0.2548861 -0.0001760563
#> p.value ci.lo method
#> <num> <num> <char>
#> 1: 1.943871e-182 4.3513453579 CPI
#> 2: 2.941635e-02 0.0007701724 CPI
#> 3: 7.024418e-178 1.6996570945 CPI
#> 4: 6.005814e-01 -0.0013127250 CPICPI with knockoffs
Since xplainfi also includes knockoffs via the
KnockoffSampler and the
KnockoffGaussianSampler, the latter implementing the second
order Gaussian knockoffs also used by default in cpi, we
can recreate its results using CFI with the corresponding
sampler.
CFI with a knockoff sampler supports CPI inference
directly via ci_method = "cpi".
knockoff_gaussian = KnockoffGaussianSampler$new(task)
cfi = CFI$new(
task = task,
learner = learner,
resampling = resampling,
measure = measure,
sampler = knockoff_gaussian,
n_repeats = 1 # generate 1 knockoff matrix, like cpi()
)
cfi$compute()
cfi_cpi_res = cfi$importance(ci_method = "cpi")
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
cfi_cpi_res
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 4.395218e+00 0.1415894276 31.04199614 5.239790e-173 4.117540158
#> 2: x2 8.896505e-05 0.0027613624 0.03221781 9.743016e-01 -0.005326485
#> 3: x3 1.778738e+00 0.0554645059 32.06983591 2.032142e-182 1.669963309
#> 4: x4 -7.539052e-05 0.0006942513 -0.10859256 9.135366e-01 -0.001436922
#> conf_upper
#> <num>
#> 1: 4.672896772
#> 2: 0.005504415
#> 3: 1.887511898
#> 4: 0.001286141
# Rename columns to match cpi package output for comparison
setnames(cfi_cpi_res, c("importance", "conf_lower"), c("CPI", "ci.lo"))
cfi_cpi_res[, method := "CFI+Knockoffs"]The results should be very similar to those computed by
cpi(), so let’s compare them:
rbindlist(list(cpi_res, cfi_cpi_res), fill = TRUE) |>
ggplot(aes(y = feature, x = CPI, color = method)) +
geom_point(position = position_dodge(width = 0.3)) +
geom_errorbar(
aes(xmin = CPI, xmax = ci.lo),
position = position_dodge(width = 0.3),
width = 0.5
) +
scale_color_brewer(palette = "Dark2") +
labs(
title = "CPI and CFI with Knockoff sampler",
subtitle = "RF with 5-fold CV",
color = NULL
) +
theme_minimal(base_size = 14) +
theme(legend.position = "top")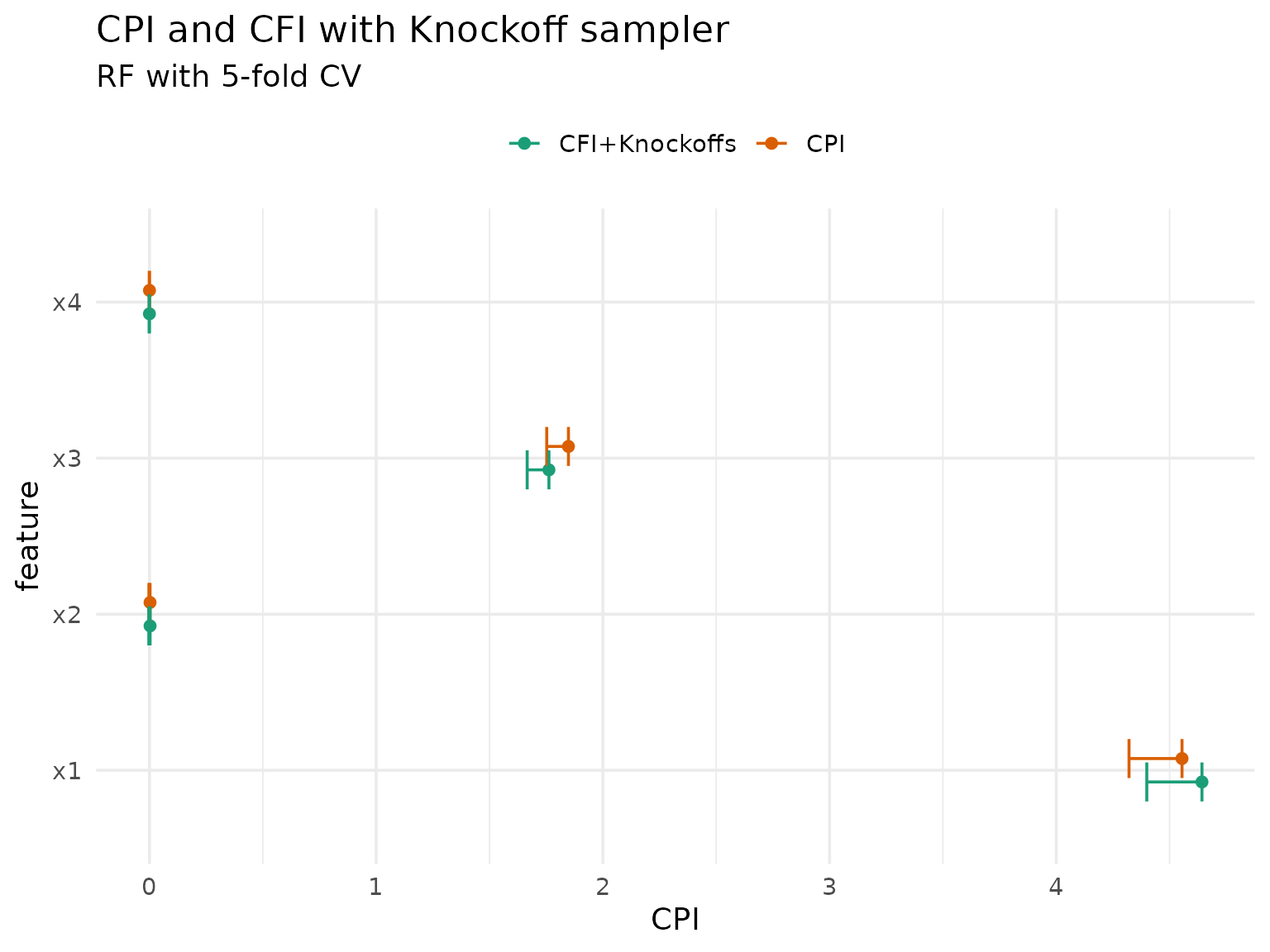
A notable caveat of the knockoff approach is that they are not readily available for mixed data (with categorical features).
cARFi: CPI with ARF
An alternative is available using ARF as conditional sampler rather than knockoffs. This approach, called cARFi, was introduced by Blesch et al. (2025) and works without Gaussian assumptions:
arf_sampler = ConditionalARFSampler$new(
task = task,
finite_bounds = "local",
min_node_size = 20,
epsilon = 1e-15
)
cfi_arf = CFI$new(
task = task,
learner = learner,
resampling = resampling,
measure = measure,
sampler = arf_sampler
)
cfi_arf$compute()
# CPI inference with ARF sampler (cARFi)
cfi_arf_res = cfi_arf$importance(ci_method = "cpi")
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
cfi_arf_res
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 4.044285644 0.0693916277 58.282040 0.000000000 3.908198155
#> 2: x2 0.006856456 0.0023740754 2.888053 0.003918033 0.002200535
#> 3: x3 1.747585238 0.0323011990 54.102798 0.000000000 1.684237696
#> 4: x4 -0.000582180 0.0005116255 -1.137903 0.255297527 -0.001585555
#> conf_upper
#> <num>
#> 1: 4.1803731337
#> 2: 0.0115123777
#> 3: 1.8109327801
#> 4: 0.0004211951
# Rename columns to match cpi package output for comparison
setnames(cfi_arf_res, c("importance", "conf_lower"), c("CPI", "ci.lo"))
cfi_arf_res[, method := "CFI+ARF"]We can now compare all three methods:
rbindlist(list(cpi_res, cfi_cpi_res, cfi_arf_res), fill = TRUE) |>
ggplot(aes(y = feature, x = CPI, color = method)) +
geom_point(position = position_dodge(width = 0.3)) +
geom_errorbar(
aes(xmin = CPI, xmax = ci.lo),
position = position_dodge(width = 0.3),
width = 0.5
) +
scale_color_brewer(palette = "Dark2") +
labs(
title = "CPI and CFI with Knockoffs and ARF",
subtitle = "RF with 5-fold CV",
color = NULL
) +
theme_minimal(base_size = 14) +
theme(legend.position = "top")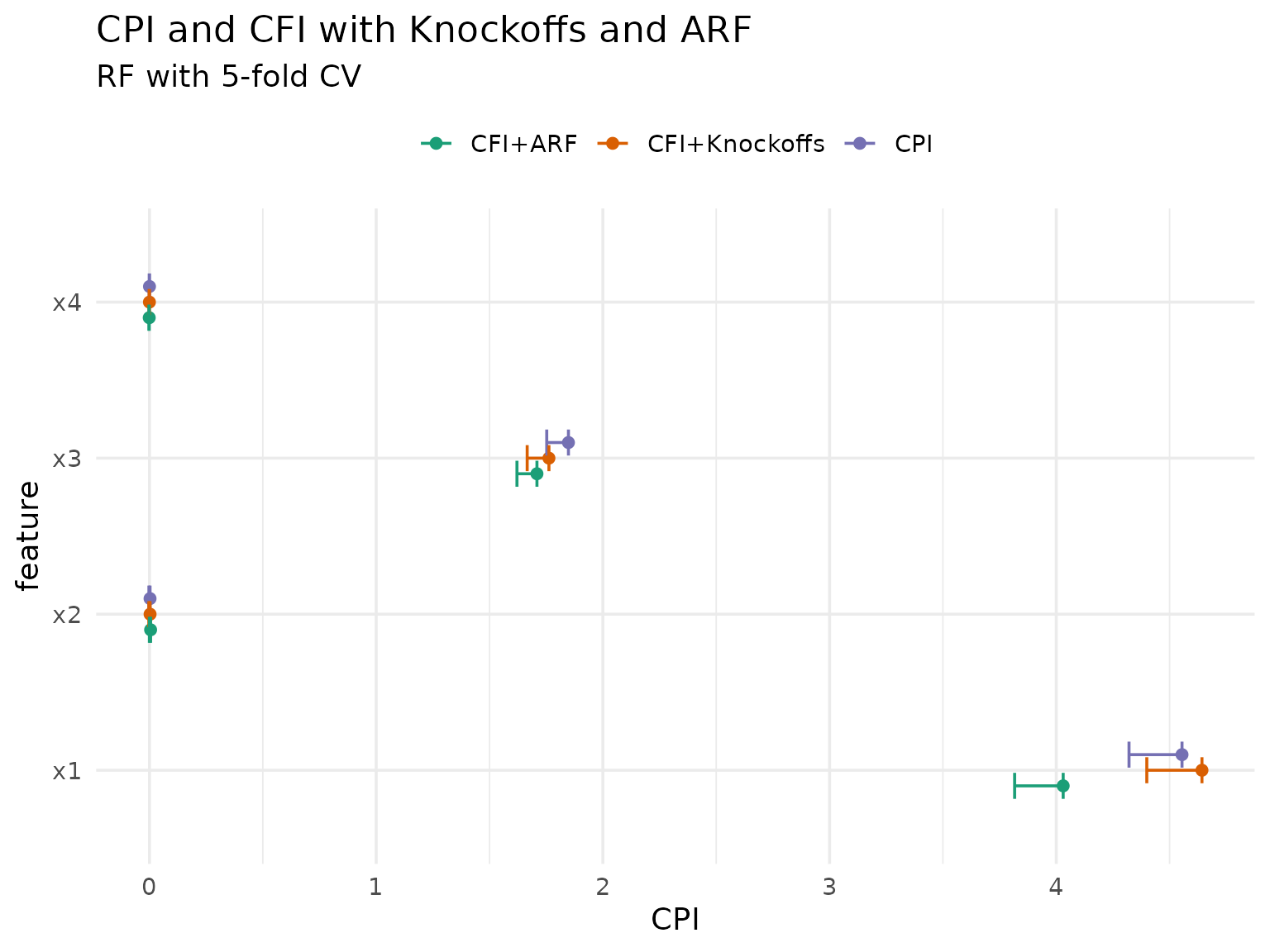
As expected, the ARF-based approach differs more from both knockoff-based approaches, but they are all roughly in agreement.
Note on resampling strategy: CPI inference was validated using holdout (a single train/test split), and inference is provably valid in this setting. With cross-validation, test observations are still i.i.d., but models are fit on overlapping training data — technically, this affects inference for the same reason the Nadeau & Bengio correction exists for resampling-based CIs. With bootstrap or subsampling, test observations may no longer be i.i.d. (due to repeated observations across test sets) and training sets overlap. In practice, Watson & Wright (2021) found that empirical results did not strongly depend on the choice of risk estimator, but inference is only guaranteed to be valid with holdout. Other resampling strategies should be employed with the understanding that coverage guarantees may not hold.
Statistical tests with CPI
CPI can also perform additional tests besides the default t-test, specifically the Wilcoxon-, Fisher-, or binomial test:
(cpi_res_wilcoxon = cfi_arf$importance(ci_method = "cpi", test = "wilcoxon"))
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
#> Key: <feature>
#> feature importance se statistic p.value conf_lower conf_upper
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: x1 4.044285644 NA 2000992 0.00000000 3.3096887486 3.5231735716
#> 2: x2 0.006856456 NA 1228176 0.00000000 0.0036493355 0.0056801550
#> 3: x3 1.747585238 NA 2000670 0.00000000 1.3988656777 1.4988176162
#> 4: x4 -0.000582180 NA 1065012 0.01250432 0.0001062227 0.0008677457
# Fisher test with same default for B as in cpi()
(cpi_res_fisher = cfi_arf$importance(ci_method = "cpi", test = "fisher", B = 1999))
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
#> Key: <feature>
#> feature importance se statistic p.value conf_lower conf_upper
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: x1 4.044285644 NA 4.044285644 0.0005 3.832263065 4.2552721488
#> 2: x2 0.006856456 NA 0.006856456 0.0025 0.002331908 0.0112049096
#> 3: x3 1.747585238 NA 1.747585238 0.0005 1.650433230 1.8452822956
#> 4: x4 -0.000582180 NA -0.000582180 0.2505 -0.001592239 0.0003824977
(cpi_res_binom = cfi_arf$importance(ci_method = "cpi", test = "binomial"))
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
#> Key: <feature>
#> feature importance se statistic p.value conf_lower conf_upper
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: x1 4.044285644 NA 1999 0.000000e+00 0.9972174 0.9999873
#> 2: x2 0.006856456 NA 1260 1.783486e-31 0.6084123 0.6512059
#> 3: x3 1.747585238 NA 1996 0.000000e+00 0.9948872 0.9994548
#> 4: x4 -0.000582180 NA 1133 2.955404e-09 0.5444474 0.5883574
rbindlist(
list(
cfi_arf$importance(ci_method = "cpi")[, test := "t"],
cpi_res_wilcoxon[, test := "Wilcoxon"],
cpi_res_fisher[, test := "Fisher"],
cpi_res_binom[, test := "Binomial"]
),
fill = TRUE
) |>
ggplot(aes(y = feature, x = importance, color = test)) +
geom_point(position = position_dodge(width = 0.3)) +
geom_errorbar(
aes(xmin = importance, xmax = conf_lower),
position = position_dodge(width = 0.3),
width = 0.5
) +
scale_color_brewer(palette = "Dark2") +
labs(
title = "CPI test with CFI/ARF",
subtitle = "RF with 5-fold CV",
color = "Test"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "top")
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.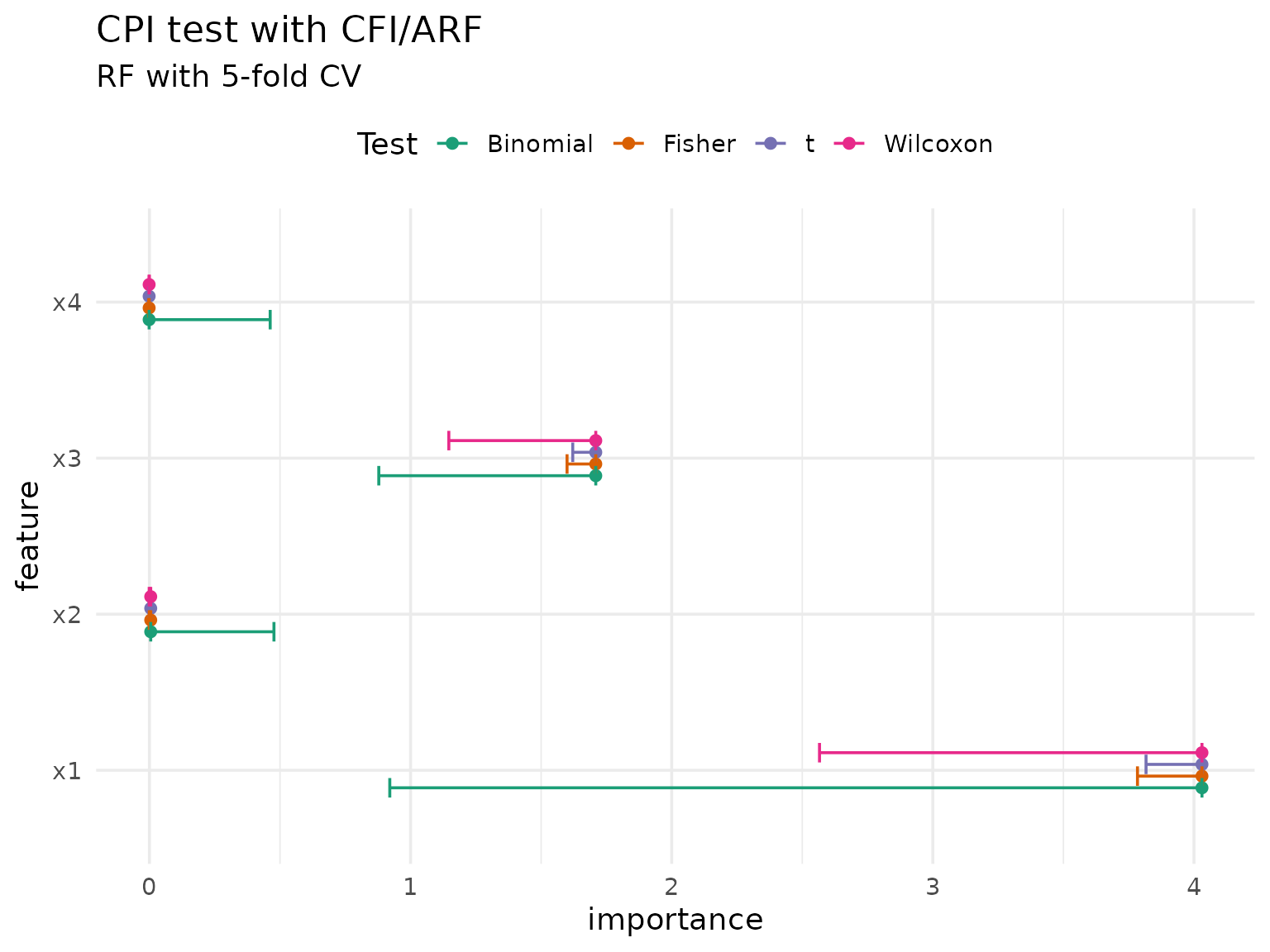
The choice of test depends on distributional assumptions: the t-test assumes normality, while Fisher and Wilcoxon are non-parametric alternatives.
Following Watson & Wright (2021), we can additionally apply
Benjamini-Hochberg FDR control (p_adjust = "BH"), which is
often desirable in exploratory settings where many features are tested
simultaneously:
cfi_arf$importance(ci_method = "cpi", p_adjust = "BH")
#> Warning: Observation-wise inference was validated with a single test set.
#> ! Current resampling has 5 iterations.
#> ℹ With cross-validation, models are fit on overlapping training data, which may
#> affect coverage.
#> ℹ With bootstrap or subsampling, test observations are not i.i.d.
#> ℹ See `vignette("inference", package = "xplainfi")` for details.
#> Key: <feature>
#> feature importance se statistic p.value conf_lower
#> <char> <num> <num> <num> <num> <num>
#> 1: x1 4.044285644 0.0693916277 58.282040 0.000000000 3.908198155
#> 2: x2 0.006856456 0.0023740754 2.888053 0.005224044 0.002200535
#> 3: x3 1.747585238 0.0323011990 54.102798 0.000000000 1.684237696
#> 4: x4 -0.000582180 0.0005116255 -1.137903 0.255297527 -0.001585555
#> conf_upper
#> <num>
#> 1: 4.1803731337
#> 2: 0.0115123777
#> 3: 1.8109327801
#> 4: 0.0004211951Note that multiplcity adjustment is in the general case limited to p-values, and only the general Bonferroni method is easily applicable to confidence intervals.
Distribution-free inference for LOCO (Lei et al., 2018)
Lei et al. (2018) proposed distribution-free inference for LOCO importance based on observation-wise loss differences. Unlike CPI/cARFi, LOCO requires retraining the model without each feature. The inference is conditional on the training data \(D_1\) from a single train/test split: the observation-wise loss differences on the test set are i.i.d. given \(D_1\), enabling nonparametric tests. The idea is to test whether the excess test error from removing feature \(j\) is significantly greater than zero:
\[ \theta_j = \mathrm{med}\left( |Y - \hat{f}_{n_1}^{-j}(X)| - |Y - \hat{f}_{n_1}(X)| \big| D_1 \right) \]
The paper proposes:
- L1 (absolute) loss as the measure
- Median as the aggregation function
- A single train/test split (holdout), since inference is conditional on the training data
- A Wilcoxon signed-rank test (or sign test) for inference
- Bonferroni correction for multiple comparisons
This is available in xplainfi via
ci_method = "lei":
# mae has L1 loss on observation-level, the "mean" aggregation is ignored here
measure_mae = msr("regr.mae")
loco = LOCO$new(
task = sim_dgp_correlated(n = 2000, r = 0.7),
learner = lrn("regr.ranger", num.trees = 500),
resampling = rsmp("holdout"),
measure = measure_mae
)
loco$compute()
loco$importance(
ci_method = "lei",
alternative = "two.sided",
p_adjust = "bonferroni",
aggregator = median # default spelled out explicitly
)
#> Key: <feature>
#> feature importance se statistic p.value conf_lower conf_upper
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: x1 0.81225612 NA 215871 0.0000000000 0.820348863 1.01307429
#> 2: x2 0.01520154 NA 131881 0.0001541243 0.008028028 0.03348111
#> 3: x3 0.54781092 NA 212234 0.0000000000 0.530080929 0.64984624
#> 4: x4 0.03491820 NA 161711 0.0000000000 0.032776320 0.05476547The ci_method = "lei" method works on observation-wise
loss differences internally, using the median as the default point
estimate and the Wilcoxon signed-rank test for confidence intervals and
p-values.
Configurable parameters
All components proposed by Lei et al. are the defaults but can be customized:
-
test:"wilcoxon"(default),"t","fisher", or"binomial"(sign test) -
aggregator: defaults tostats::median, can be changed (e.g.mean) -
p_adjust: p-value correction for multiple comparisons, accepts any method fromstats::p.adjust.methods(e.g."bonferroni","holm","BH","none"). Default is"none". When"bonferroni", confidence intervals are also adjusted (alpha/k). For other methods like"holm"or"BH", only p-values are adjusted because these sequential/adaptive procedures do not yield a clean per-comparison alpha for CI construction.
loco$importance(
ci_method = "lei",
test = "t",
aggregator = mean,
alternative = "two.sided",
p_adjust = "holm"
)
#> Key: <feature>
#> feature importance se statistic p.value conf_lower conf_upper
#> <char> <num> <num> <num> <num> <num> <num>
#> 1: x1 0.98739703 0.035505917 27.809365 5.927253e-113 0.91768001 1.05711405
#> 2: x2 0.03090397 0.006890632 4.484926 8.589484e-06 0.01737399 0.04443395
#> 3: x3 0.62008650 0.022543449 27.506283 2.210494e-111 0.57582171 0.66435129
#> 4: x4 0.05813815 0.005337653 10.892082 3.089219e-25 0.04765749 0.06861880