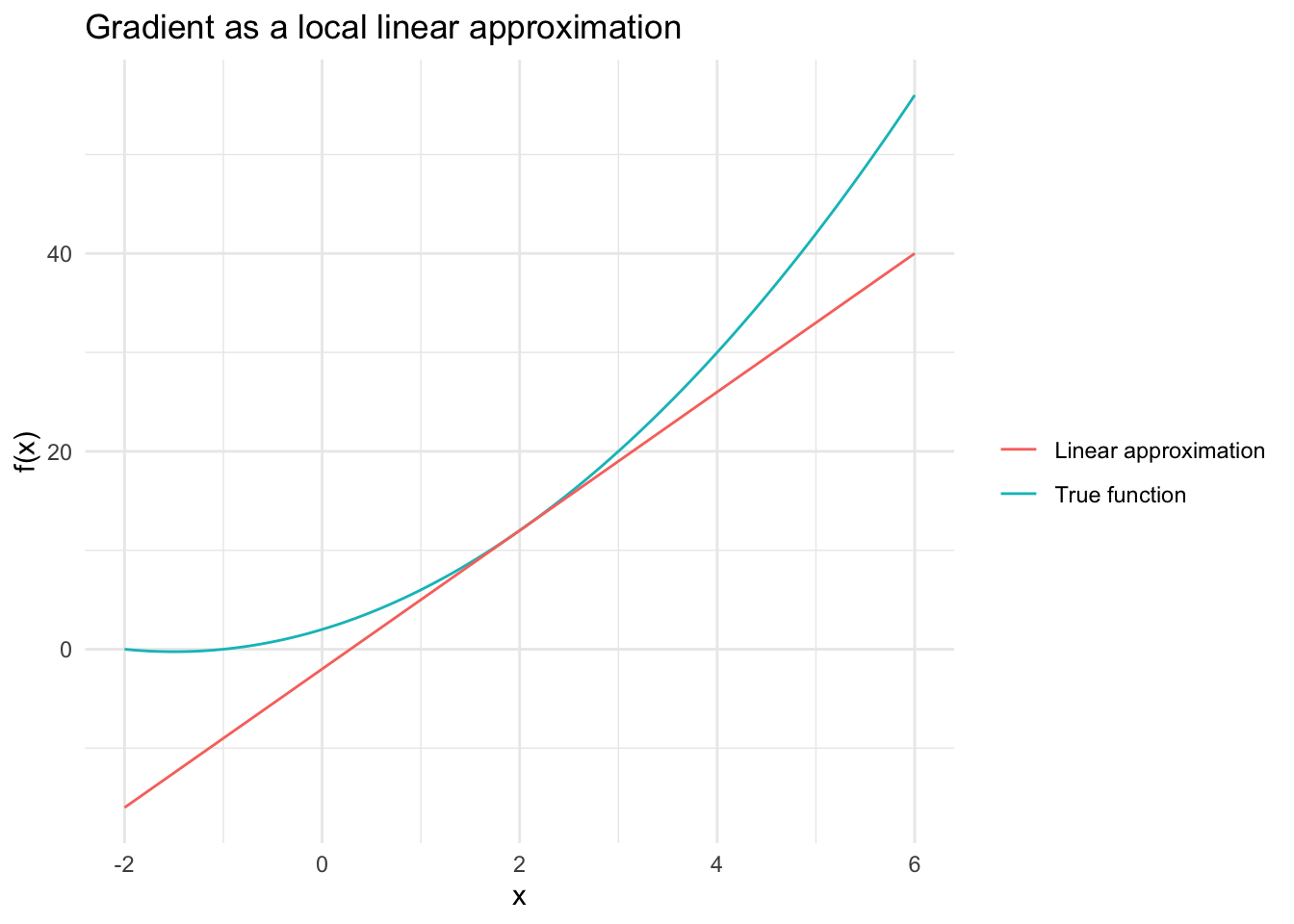
Plot the function from earlier as well as the local linear approximation at \(x = 2\) using ggplot2.
Hint
To do so, follow these steps:
Create a sequence with 100 equidistant values between -4 to 4 using torch_linspace().
Create the true function values at these points using the function from exercise 1.
Approximate the function using the formula \(f(x^* + \delta) \approx f(x^*) + f'(x^*) \cdot \delta\).
Create a data.frame with columns x, y_true, y_approx.
Use ggplot2 to plot the function and its linear approximation.
Solution
library(ggplot2)x <- x$detach() # No need to track gradients anymoredeltas <-torch_linspace(-4, 4, 100)y_true <-f(x + deltas)y_approx <-f(x) + grad * deltasd <-data.frame(x =as_array(x + deltas), y_true =as_array(y_true), y_approx =as_array(y_approx))ggplot(d, aes(x = x)) +geom_line(aes(y = y_true, color ="True function")) +geom_line(aes(y = y_approx, color ="Linear approximation")) +theme_minimal() +labs(title ="Gradient as a local linear approximation",y ="f(x)",x ="x",colour ="" )
Question 3: Look ma, I made my own autograd function
In this exercise, we will build our own, custom autograd function. While you might rarely need this in practice, it still allows you to get a better understanding of how the autograd system works. There is also a tutorial on this on the torchwebsite.
To construct our own autograd function, we need to define:
The forward pass:
How to calculate outputs from inputs
What to save for the backward pass
The backward pass:
How to calculate the gradient of the output with respect to the inputs, using the information saved during the forward pass
The task is to re-create the ReLU activation function, which is a common activation function in neural networks and which is defined as:
\[
\text{ReLU}(x) = \max(0, x)
\]
Note that strictly speaking, the ReLU function is not differentiable at \(x = 0\) (but a subgradient can be used instead). The derivative/subgradient of the ReLU function is:
In torch, a custom autograd function can be constructed using autograd_function() and it accepts arguments forward and backward which are functions that define the forward and backward pass: They both take as first argument a ctx, which is a communication object that is used to save information during the forward pass to be able to compute the gradient in the backward pass (e.g. for \(f(x) = x \times a\), to calculate the gradient of \(f\) with respect to \(a\) we need to know the input value \(x\)). The return value of the backward pass should be a list of gradients of the final node of the autograd graph with respect to the inputs. To check whether a gradient for an input is needed (has requires_grad = TRUE), you can use ctx$needs_input_grad which is a named list with boolean values for each input.
The backward function additionally takes a second argument grad_output, which is the gradient of the output: E.g., if our function is \(f(x)\) and we calculate the gradient of \(g(x) = h(f(x))\), then grad_output is the derivative of \(h\) with respect to its input, evaluated at \(f(x)\). This is essentially the chain rule: \(\frac{\partial g}{\partial x} = \frac{\partial h}{\partial f} \cdot \frac{\partial f}{\partial x}\). The $backward() method of the autograd function \(f\) would in this case therefore not return \(\frac{\partial f}{\partial x}\), but \(\frac{\partial g}{\partial x}\).
Fill out the missing parts (...) in the code below.